

Quantinuum H-Series quantum computer accelerates through 3 more performance records for quantum volume
217, 218, and 219
In the last 6 months, Quantinuum H-Series hardware has demonstrated explosive performance improvement. Quantinuum’s System Model H1-1, Powered by Honeywell, has demonstrated going from 214 = 16,384 quantum volume (QV) announced in February 2023 to now 219 = 524,288, with all the details and data released on our GitHub repository for full transparency. At a quantum volume of 524,288, H1-1 is 1000x higher than the next best reported quantum volume.


We set a big goal back in 2020 when we launched our first quantum computer, HØ. HØ was launched with six qubits and a quantum volume of 26 = 64, and at that time we made the bold and audacious commitment to increasing the quantum volume of our commercial machines 10x per year for 5 years, equating to a quantum volume of 8,388,608 or 223 by the end of 2025. In an industry that is often accused of being over-hyped, a commitment like this was easy to forget. But we did not forget. Diligently, our scientists and engineers continued to achieve world-record after world-record in a tireless and determined pursuit to systematically improve the overall performance of our quantum computers. As seen in Figure 1, from 2020 to early 2023, we have steadily been increasing the quantum volume to demonstrate that increased qubit count while reducing errors directly translates to more computational power. Just within 2023 we’ve had multiple announcements of quantum volume improvements. In February we announced that H1-1 had leapfrogged 214 and achieved a quantum volume of 215. In May 2023, we launched H2-1 with 32 qubits at a quantum volume of 216. Now we are thrilled to announce the sequential improvements of 217, 218, and 219, all on H1-1.
Importantly, none of these results were “hero results”, meaning there are no special calibrations made just to try to make the system look better. Our quantum volume data is taken on our commercial systems interwoven with customer jobs. What we experience is what our customers experience. Instead of improving at 10x per year as we committed back in 2020, the pace of improvement over the past 6 months has been 30x, accelerating at least one year from our 5-year commitment. While these demonstrations were made using H1-1, the similarities in the designs of H1-2 (now upgraded with 20 qubits) and H2-1, our recently released second generation system, make it straightforward to share the improvements from one machine to another and achieve the same results.
In this young and rapidly evolving industry, there are and will be disagreements about which benchmarks are best to use. Quantum volume, developed by IBM, is undeniably rigorous. Quantum volume can be measured on any gate-based machine. Quantum volume has been peer-reviewed and has well defined assumptions and processes for making the measurements. Improvements in QV require consistent reductions in errors, making it likely that no matter the application, QV improvements translate to better performance. In fact, to realize the exponential increase in power that quantum computers promise, it is required to continue to reduce these error rates. The average two-qubit gate error with these three new QV demonstrations was 0.13%, the best in the industry. We measure many benchmarks, but it is for these reasons that we have adopted quantum volume as our primary system-wide benchmark to report our performance.
Putting aside the argument of which benchmark is better, year-over-year improvements in a rigorous benchmark do not happen accidentally. It can only happen because the dedicated, talented scientists and engineers that work on H-Series hardware have a deep understanding of its error model and a deep understanding of how to reduce the errors to make overall performance improvements. Equally important the talented scientists and engineers have mastery of their domain expertise and can dream-up and then implement the improvements. These validated error models become the bedrock of future systems’ design, instilling confidence that those systems will have well understood error models, and the performance of those systems can also be systematically improved and ultimate performance goals achieved. Taking nothing away from those talented scientists and engineers, but having perfect, identical qubits and employing our quantum charge coupled device (QCCD) architecture does give us an advantage that all the other architectures and other modalities do not have.
What should potential users of H-Series quantum computers take away from this write-up (and what do current users already know)?
- Quantinuum is committed to systematically improving the core performance of our quantum computing hardware. The better the fundamental performance, the lower the overhead will be when doing error mitigation, error detection, and ultimately error correction. This provides confidence in our ability to deliver fault-tolerant compute capabilities.
- Progress on your research, use-case, or application can be accelerated by getting access to H-series technology because our quantum computers can do circuits that other technologies cannot. “It actually works!” exclaim excited first-time users.
- Quantinuum intends to continue to be the quantum computing company that quietly over-delivers, even on big goals.
1. https://github.com/CQCL/quantinuum-hardware-quantum-volume
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
- Researchers from Quantinuum, Caltech, the University of Chicago, and Harvard created a rare topologically ordered state of matter on Quantinuum's System Model H2 and used it to perform protected universal quantum gates with non-Abelian anyons.
- The work explores an alternative approach to fault tolerance by using topological properties to protect quantum information. This could reduce the need for magic state distillation, which can (in some circumstances) be resource-intensive.
- Quantinuum continues to show leadership in fault tolerance, with successful demonstrations spanning world record error rates to exotic approaches like topological computing
Quantum computing is all about putting the exotic properties of physics to work. Qubits can exist in two states at once, like the famous cat that is both alive and dead. Qubits can also be entangled, where the state of one will instantaneously affect the state of another - even when they have no way to “talk” to each other. Qubits can even be teleported, moving a quantum state from one place to another without physically moving it through space.
These features give quantum computing its power. But the ‘spooky’ nature of quantum computing doesn’t stop there: our quantum computers are potent enough to make exotic states of matter out of our qubits, and to perform calculations that would warp the mind of more traditional thinkers.
A new approach
In a recent paper published in Nature, researchers at Quantinuum teamed up with Caltech, the University of Chicago, and Harvard to create a rare ‘topologically ordered’ state of matter from our qubits.
When the qubits become ‘topologically ordered’, they become more than individual particles, now ‘related’ to each other in a specific way. This is like how hydrogen and oxygen act as individual gas particles alone, but you can put them together in a certain way so that they become water, a liquid, and an entirely different creature.
When the qubits become topologically ordered, the quantum information that they carried individually gets spread out over the whole system, which acts as a sort of protection from noise. This is like how a net makes a stronger barrier than a bunch of un-knotted ropes.
Once the researchers had topologically ordered qubits, they used the exotic particles that resulted (called non-Abelian anyons) to compute, performing error-protected gates and measurements.
To perform gates, the researchers 'braided' the anyons, which is like changing the shape of the “net”. This is something like the children’s game ‘cats cradle’. Through a sequence of changes to the “net”, the quantum computer can perform full calculations, one day helping scientists to understand the secrets hidden in the world around us.
Why go to such trouble? Well, for the love of discovery of course - but the team had an additional, specific motivation. One of the biggest challenges in building practical quantum computers is protecting them from errors while still being able to perform every operation needed for computation (this is referred to as universality).
This work takes a fresh approach to this challenge. Unlike traditional quantum error correction, the special properties of topological matter enable a universal set of fault tolerant gates without relying on expensive magic state distillation.
Why this matters
Quantum error correction is essential for large-scale quantum computing. While it protects fragile quantum information from noise by turning delicate physical qubits into robust logical qubits, it also introduces a significant constraint: not every quantum gate can be performed directly on logical qubits.
For decades, the standard solution has been to supplement error-corrected operations with magic states. These specially prepared quantum resources enable universal computation but can come at a steep cost - in many estimates of future fault-tolerant quantum computers, magic state preparation dominates both the physical qubit count and the runtime of useful algorithms.
Reducing this overhead has therefore become an important goal in quantum computing. This new approach may significantly reduce the cost by enabling the ‘topological preparation’ of magic states, eliding expensive protocols like distillation. If universal computation can be performed without large-scale magic state distillation, quantum computers could require significantly fewer physical qubits and spend much less time generating computational resources before running useful algorithms.
We will never stop exploring
While there is still considerable work ahead to understand the practical implementation and scalability of these ideas, this result expands the landscape of what's possible in quantum fault tolerance.
Of course, this impressive demonstration describes just one approach we are taking to fault tolerance at scale. We will continue to push forward with topological computing alongside more traditional approaches to quantum error correction, as well as exploring everything we can imagine in between. We are looking at a number of ways to reduce the resource cost of magic states in particular, and are making strides in multiple dimensions. With machines that are both flexible and accurate enough to do it all, who can resist?
- Quantinuum continues its progress toward fault-tolerant quantum computing, with a series of peer-reviewed breakthroughs in fault-tolerant operations.
- Our progress is not only scientific; it is commercial. By improving logical-qubit reliability and encoding efficiency, Quantinuum is reducing the resource overhead required to scale its quantum computers toward commercially useful workloads.
- These results were achieved on commercial Quantinuum hardware, reinforcing that our architecture is not just setting new standards, but building a practical foundation for customers, partners, and researchers preparing for the fault-tolerant era.
Fault-tolerant quantum computing is the threshold the industry must cross before quantum computers can solve the hardest, highest-value problems with confidence. To be commercially useful at scale, the question is not simply who can build more qubits. It is who can build reliable, efficient, scalable systems that reduce technical risk and accelerate the path to commercial usefulness.
Quantinuum is progressing on that path.
Last year, in partnership with Microsoft, we published a breakthrough in logical computing, demonstrating logical qubits that outperformed their physical counterparts by a factor of 800. We are proud to announce that this work is now being published in Nature, one of the most highly regarded scientific journals in the world.
This work highlights our leading fidelities, as shown in Table 1:
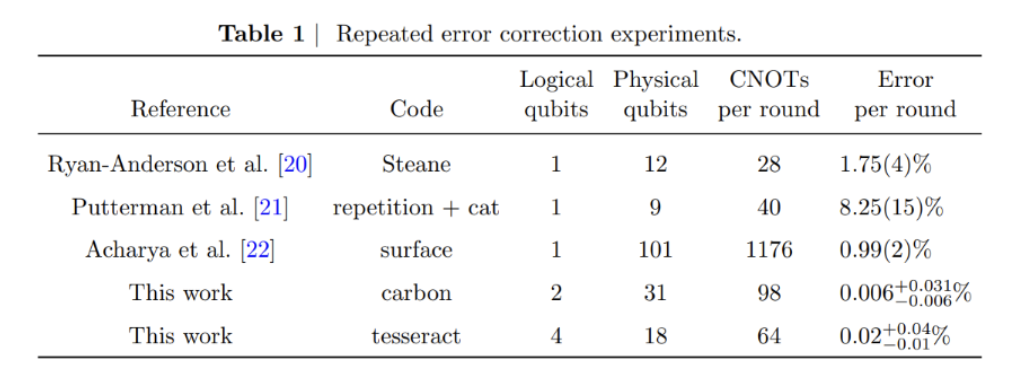
Since then, we’ve accelerated our efforts to reach large-scale fault tolerance and advanced what we believe to be the core building blocks of fault-tolerant quantum computing, from logical-qubit teleportation and multiple error-correction breakthroughs to one of the first meaningful computations using logical qubits. Importantly, these results were achieved on commercial Quantinuum hardware, demonstrating not just scientific progress, but a practical and efficient path toward scalable, customer-ready fault tolerance.
A Recap of Our Recent Technical Progress
Since the work with Microsoft, we achieved a milestone years ahead of schedule, demonstrating high-fidelity teleportation of a logical qubit, which was published in Science, one of the world’s most prestigious journals. Later, we beat our own record in this crucial fault tolerance milestone, thanks to continued improvements to our System Model H2’s fidelity.
Then, a series of results demonstrating more error-correcting milestones (and codes):
- Better than physical results in a high-rate non-local code,
- First-ever demonstration of a single-shot error correcting code (which significantly reduces resource requirements) in 4 dimensions
- Extending qubit lifetimes by 10x with a concatenated code
- Observed fault-tolerance thresholds with concatenated codes
- High fidelity magic states and a fully fault tolerant universal gate set in two different papers
Recently, we topped ourselves yet again by performing one of the first meaningful computations with logical qubits – exploring key questions in materials and magnetism, using logical qubits with better error rates than their physical counterparts. This result also includes a leading “encoding rate” squeezing 48 logical qubits out of just 98 physical qubits, emphasizing how our architecture helps to support large scale fault tolerance without enormous resource costs.
It is worth noting that all these results were achieved on our commercial hardware, not on one-off laboratory test-stands – reflecting the performance that we are able to deliver to our customers.
We also did crucial theoretical work, exploring new options for error correction that can reduce resource requirements, time to solution, and shorten the timeline to large scale fault tolerance.
Commercial Implications and the Road Ahead
We believe the commercial implication is clear: Quantinuum is reducing the uncertainty around the path to fault-tolerant quantum computing. Our architecture, hardware fidelity, full-stack control, and error-correction progress are converging into a practical roadmap for systems that can support valuable scientific and commercial workloads.
For those evaluating when quantum computing will become strategically relevant, we believe the signal is also increasingly clear: the fault-tolerant era is no longer a distant concept. It is becoming an engineering reality, and Quantinuum is leading the way.
- University of Southern Denmark (SDU) to use Quantinuum Helios, supported by the Danish e-Infrastructure Consortium (DeiC)
- Access to Helios enables SDU to test and refine fault-tolerant algorithms and error-correction codes under realistic hardware conditions
- The collaboration supports at a scale of 48 logical qubits, positioning Denmark at the forefront of scalable, practical quantum computing
- Researchers exploring the scientific foundations for future development of applications in fields including pharmaceuticals, finance, and defense
Progress in quantum computing is measured by hardware advances plus the algorithms and quantum error-correction codes that turn quantum systems into useful computational tools.
Thanks to recent hardware advances, researchers are increasingly sharpening their tools to probe the performance of quantum algorithms and understand how they behave in realistic conditions – where stability, system architecture and algorithm design all shape performance.
A new Denmark-based collaboration between the University of Southern Denmark (SDU), Quantinuum, and the Danish e-Infrastructure Consortium (DeiC) will utilize Quantinuum Helios. Researchers at the SDU’s Centre for Quantum Mathematics, led by Jørgen Ellegaard Andersen, will use Helios to pursue research into topological quantum computing.
Their work could help explain how and why successful quantum algorithms perform as they do, informing the development of high-performance algorithms suited to emerging quantum systems. They’re exploring the scientific foundations that support future quantum applications across areas including pharmaceuticals, finance, and defense.
“We are thrilled to gain access to Quantinuum’s high-fidelity Helios system. This collaboration gives us a unique opportunity to test the limits of our algorithms and evaluate system performance, while advancing fundamental research and laying the foundation for future applications.”
— Professor Jørgen Ellegaard Andersen, Director of the Centre for Quantum Mathematics at University of Southern Denmark
Why topological methods matter
Topological quantum computing is an area of research that connects quantum computation with deep mathematical structures. It includes the study of error correcting codes known as surface codes that encode quantum information in the global properties of systems of logical qubits.
The research team will explore how these codes behave, and how they may support the development of fault-tolerant quantum algorithms in practical implementations under realistic conditions.
This distinction between theory and practical implementation matters. In theory, topological approaches offer a rich framework for designing algorithms and error-correcting codes. In practice, researchers need to understand how those ideas perform when implemented on real systems, where questions of noise, stability, overhead, and scaling become central. The collaboration will allow the SDU team to investigate these questions directly.
New ways to benchmark quantum processors
Beyond individual algorithms and codes, the research will also develop tools for benchmarking quantum processors. The goal is to develop new ways to characterize fidelity and stability in regimes that can be difficult to access.
The team will also explore hybrid quantum–classical approaches, including machine-learning techniques assisted by quantum hardware, to study the mathematical structures at the heart of topological quantum computing. This work reflects a broader field of research in which quantum and classical methods are used together, each contributing to parts of a computational problem.
Strengthening Denmark’s quantum ecosystem
The collaboration reflects the growing role of national quantum infrastructure in supporting research and talent development. Denmark has a long tradition of scientific innovation, and this collaboration is intended to support the country’s continued development in quantum technology.
The initiative is supported by DeiC, which played a central role in securing funding and enabling access to Quantinuum’s systems. DeiC has been assigned a particular role in developing and coordinating quantum infrastructure initiatives for the benefit of universities and industry, operating without its own commercial, sectoral, or geographical interests. This includes securing dedicated access to quantum computers, producing advisory services and supporting the development of new talent in the Danish quantum sector.
“DeiC’s special effort to secure funding and access for this research initiative is rooted in our organization’s role in relation to the Danish Government’s strategy for quantum technology.”
— Henrik Navntoft Sønderskov, Head of Quantum at Danish e-Infrastructure Consortium
This collaboration promises to accelerate the development of practical algorithms. It is grounded in fundamental science – but its focus is practical: discovering and testing mathematical approaches to topological quantum computing that can be implemented, evaluated, and improved on real quantum hardware.
That work requires both theoretical insight and access to a system such as Helios capable of supporting meaningful scientific work.