

Quantum Volume reaches 5 digits for the first time
5 perspectives on what it means for quantum computing
Quantinuum’s H-Series team has hit the ground running in 2023, achieving a new performance milestone. The H1-1 trapped ion quantum computer has achieved a Quantum Volume (QV) of 32,768 (215), the highest in the industry to date.
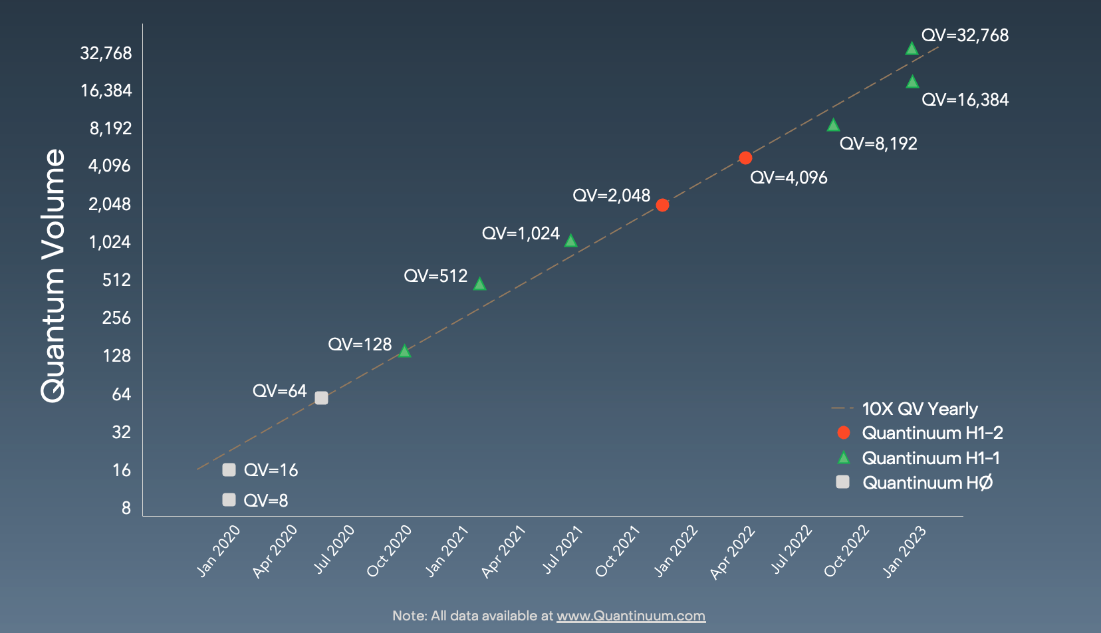
The team previously increased the QV to 8,192 (or 213) for the System Model H1 system in September, less than six months ago. The next goal was a QV of 16,384 (214). However, continuous improvements to the H1-1's controls and subsystems advanced the system enough to successfully reach 214 as expected, and then to go one major step further, and reach a QV of 215.
The Quantum Volume test is a full-system benchmark that produces a single-number measure of a quantum computer’s general capability. The benchmark takes into account qubit number, fidelity, connectivity, and other quantities important in building useful devices.1 While other measures such as gate fidelity and qubit count are significant and worth tracking, neither is as comprehensive as Quantum Volume which better represents the operational ability of a quantum computer.
Dr. Brian Neyenhuis, Director of Commercial Operations, credits reductions in the phase noise of the computer’s lasers as one key factor in the increase.
"We've had enough qubits for a while, but we've been continually pushing on reducing the error in our quantum operations, specifically the two-qubit gate error, to allow us to do these Quantum Volume measurements,” he said.
The Quantinuum team improved memory error and elements of the calibration process as well.
“It was a lot of little things that got us to the point where our two-qubit gate error and our memory error are both low enough that we can pass these Quantum Volume circuit tests,” he said.
The work of increasing Quantum Volume means improving all the subsystems and subcomponents of the machine individually and simultaneously, while ensuring all the systems continue to work well together. Such a complex task takes a high degree of orchestration across the Quantinuum team, with the benefits of the work passed on to H-Series users.
To illustrate what this 5-digit Quantum Volume milestone means for the H-Series, here are 5 perspectives that reflect Quantinuum teams and H-Series users.
Perspective #1: How a higher QV impacts algorithms
Dr. Henrik Dreyer is Managing Director and Scientific Lead at Quantinuum’s office in Munich, Germany. In the context of his work, an improvement in Quantum Volume is important as it relates to gate fidelity.
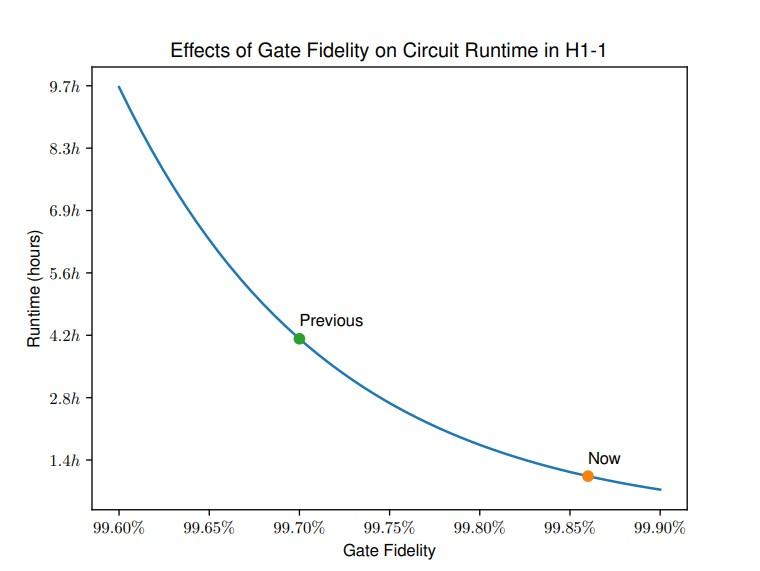
“As application developers, the signal-to-noise ratio is what we're interested in,” Henrik said. “If the signal is small, I might run the circuits 10 times and only get one good shot. To recover the signal, I have to do a lot more shots and throw most of them away. Every shot takes time."
“The signal-to-noise ratio is sensitive to the gate fidelity. If you increase the gate fidelity by a little bit, the runtime of a given algorithm may go down drastically,” he said. “For a typical circuit, as the plot shows, even a relatively modest 0.16 percentage point improvement in fidelity, could mean that it runs in less than half the time.”
To demonstrate this point, the Quantinuum team has been benchmarking the System Model H1 performance on circuits relevant for near-term applications. The graph below shows repeated benchmarking of the runtime of these circuits before and after the recent improvement in gate fidelity. The result of this moderate change in fidelity is a 3x change in runtime. The runtimes calculated below are based on the number of shots required to obtain accurate results from the benchmarking circuit – the example uses 430 arbitrary-angle two-qubit gates and an accuracy of 3%.
Perspective #2: Advancing quantum error correction
Dr. Natalie Brown and Dr, Ciaran Ryan-Anderson both work on quantum error correction at Quantinuum. They see the QV advance as an overall boost to this work.
“Hitting a Quantum Volume number like this means that you have low error rates, a lot of qubits, and very long circuits,” Natalie said. “And all three of those are wonderful things for quantum error correction. A higher Quantum Volume most certainly means we will be able to run quantum error correction better. Error correction is a critical ingredient to large-scale quantum computing. The earlier we can start exploring error correction on today’s small-scale hardware, the faster we’ll be able to demonstrate it at large-scale.”
Ciaran said that H1-1's low error rates allow scientists to make error correction better and start to explore decoding options.
“If you can have really low error rates, you can apply a lot of quantum operations, known as gates,” Ciaran said. "This makes quantum error correction easier because we can suppress the noise even further and potentially use fewer resources to do it, compared to other devices.”
Perspective #3: Meeting a high benchmark
“This accomplishment shows that gate improvements are getting translated to full-system circuits,” said Dr. Charlie Baldwin, a research scientist at Quantinuum.
Charlie specializes in quantum computing performance benchmarks, conducting research with the Quantum Economic Development Consortium (QED-C).
“Other benchmarking tests use easier circuits or incorporate other options like post-processing data. This can make it more difficult to determine what part improved,” he said. “With Quantum Volume, it’s clear that the performance improvements are from the hardware, which are the hardest and most significant improvements to make.”
“Quantum Volume is a well-established test. You really can’t cheat it,” said Charlie.
Perspective #4: Implications for quantum applications
Dr. Ross Duncan, Head of Quantum Software, sees Quantum Volume measurements as a good way to show overall progress in the process of building a quantum computer.
“Quantum Volume has merit, compared to any other measure, because it gives a clear answer,” he said.
“This latest increase reveals the extent of combined improvements in the hardware in recent months and means researchers and developers can expect to run deeper circuits with greater success.”
Perspective #5: H-Series users
Quantinuum’s business model is unique in that the H-Series systems are continuously upgraded through their product lifecycle. For users, this means they continually and immediately get access to the latest breakthroughs in performance. The reported improvements were not done on an internal testbed, but rather implemented on the H1-1 system which is commercially available and used extensively by users around the world.
“As soon as the improvements were implemented, users were benefiting from them,” said Dr. Jenni Strabley, Sr. Director of Offering Management. “We take our Quantum Volume measurement intermixed with customers’ jobs, so we know that the improvements we’re seeing are also being seen by our customers.”
Jenni went on to say, “Continuously delivering increasingly better performance shows our commitment to our customers’ success with these early small-scale quantum computers as well as our commitment to accuracy and transparency. That’s how we accelerate quantum computing.”
Supporting data from Quantinuum’s 215 QV milestone
This latest QV milestone demonstrates how the Quantinuum team continues to boost the performance of the System Model H1, making improvements to the two-qubit gate fidelity while maintaining high single-qubit fidelity, high SPAM fidelity, and low cross-talk.
The average single-qubit gate fidelity for these milestones was 99.9955(8)%, the average two-qubit gate fidelity was 99.795(7)% with fully connected qubits, and state preparation and measurement fidelity was 99.69(4)%.
For both tests, the Quantinuum team ran 100 circuits with 200 shots each, using standard QV optimization techniques to yield an average of 219.02 arbitrary angle two-qubit gates per circuit on the 214 test, and 244.26 arbitrary angle two-qubit gates per circuit on the 215 test.
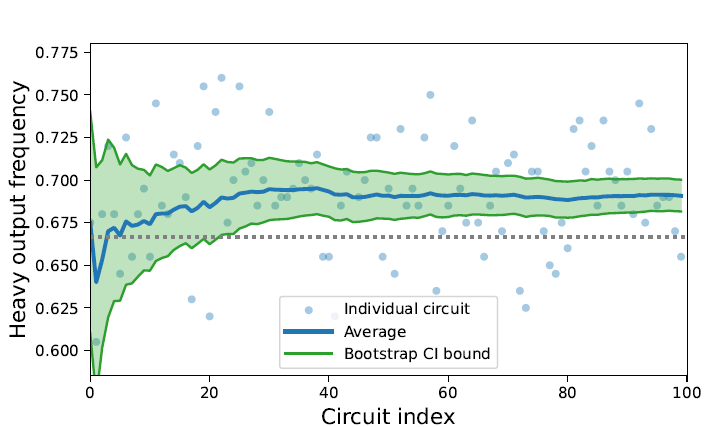
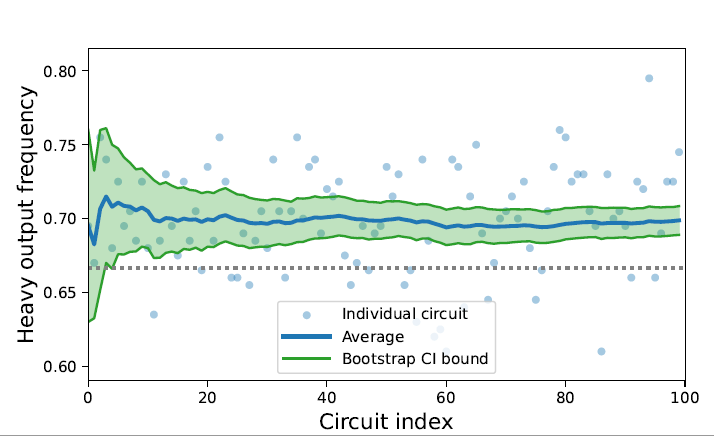
The Quantinuum H1-1 successfully passed the quantum volume 16,384 benchmark, outputting heavy outcomes 69.88% of the time, and passed the 32,768 benchmark, outputting heavy outcomes 69.075% of the time. The heavy output frequency is a simple measure of how well the measured outputs from the quantum computer match the results from an ideal simulation. Both results are above the two-thirds passing threshold with high confidence. More details on the Quantum Volume test can be found here.
Heavy output frequency for H1-1 at 215 (QV 32,768)
Heavy output frequency for H1-1 at 214 (QV 16,384)
Quantum Volume data and analysis code can be accessed on Quantinuum’s GitHub repository for quantum volume data. Contemporary benchmarking data can be accessed at Quantinuum’s GitHub repository for hardware specifications.
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
Last year, we joined forces with RIKEN, Japan's largest comprehensive research institution, to install our hardware at RIKEN’s campus in Wako, Saitama. This deployment is part of RIKEN’s project to build a quantum-HPC hybrid platform consisting of high-performance computing systems, such as the supercomputer Fugaku and Quantinuum Systems.
Today, a paper published in Physical Review Research marks the first of many breakthroughs coming from this international supercomputing partnership. The team from RIKEN and Quantinuum joined up with researchers from Keio University to show that quantum information can be delocalized (scrambled) using a quantum circuit modeled after periodically driven systems.
"Scrambling" of quantum information happens in many quantum systems, from those found in complex materials to black holes. Understanding information scrambling will help researchers better understand things like thermalization and chaos, both of which have wide reaching implications.
To visualize scrambling, imagine a set of particles (say bits in a memory), where one particle holds specific information that you want to know. As time marches on, the quantum information will spread out across the other bits, making it harder and harder to recover the original information from local (few-bit) measurements.
While many classical techniques exist for studying complex scrambling dynamics, quantum computing has been known as a promising tool for these types of studies, due to its inherently quantum nature and ease with implementing quantum elements like entanglement. The joint team proved that to be true with their latest result, which shows that not only can scrambling states be generated on a quantum computer, but that they behave as expected and are ripe for further study.
Thanks to this new understanding, we now know that the preparation, verification, and application of a scrambling state, a key quantum information state, can be consistently realized using currently available quantum computers. Read the paper here, and read more about our partnership with RIKEN here.
In our increasingly connected, data-driven world, cybersecurity threats are more frequent and sophisticated than ever. To safeguard modern life, government and business leaders are turning to quantum randomness.
What is quantum randomness, and why should you care?
The term to know: quantum random number generators (QRNGs).
QRNGs exploit quantum mechanics to generate truly random numbers, providing the highest level of cryptographic security. This supports, among many things:
- Protection of personal data
- Secure financial transactions
- Safeguarding of sensitive communications
- Prevention of unauthorized access to medical records
Quantum technologies, including QRNGs, could protect up to $1 trillion in digital assets annually, according to a recent report by the World Economic Forum and Accenture.
Which industries will see the most value from quantum randomness?
The World Economic Forum report identifies five industry groups where QRNGs offer high business value and clear commercialization potential within the next few years. Those include:
- Financial services
- Information and communication technology
- Chemicals and advanced materials
- Energy and utilities
- Pharmaceuticals and healthcare
In line with these trends, recent research by The Quantum Insider projects the quantum security market will grow from approximately $0.7 billion today to $10 billion by 2030.
When will quantum randomness reach commercialization?
Quantum randomness is already being deployed commercially:
- Early adopters use our Quantum Origin in data centers and smart devices.
- Amid rising cybersecurity threats, demand is growing in regulated industries and critical infrastructure.
Recognizing the value of QRNGs, the financial services sector is accelerating its path to commercialization.
- Last year, HSBC conducted a pilot combining Quantum Origin and post-quantum cryptography to future-proof gold tokens against “store now, decrypt-later” (SNDL) threats.
- And, just last week, JPMorganChase made headlines by using our quantum computer for the first successful demonstration of certified randomness.
On the basis of the latter achievement, we aim to broaden our cybersecurity portfolio with the addition of a certified randomness product in 2025.
How is quantum randomness being regulated?
The National Institute of Standards and Technology (NIST) defines the cryptographic regulations used in the U.S. and other countries.
- NIST’s SP 800-90B framework assesses the quality of random number generators.
- The framework is part of the FIPS 140 standard, which governs cryptographic systems operations.
- Organizations must comply with FIPS 140 for their cryptographic products to be used in regulated environments.
This week, we announced Quantum Origin received NIST SP 800-90B Entropy Source validation, marking the first software QRNG approved for use in regulated industries.
What does NIST validation mean for our customers?
This means Quantum Origin is now available for high-security cryptographic systems and integrates seamlessly with NIST-approved solutions without requiring recertification.
- Unlike hardware QRNGs, Quantum Origin requires no network connectivity, making it ideal for air-gapped systems.
- For federal agencies, it complements our "U.S. Made" designation, easing deployment in critical infrastructure.
- It adds further value for customers building hardware security modules, firewalls, PKIs, and IoT devices.
The NIST validation, combined with our peer-reviewed papers, further establishes Quantum Origin as the leading QRNG on the market.
--
It is paramount for governments, commercial enterprises, and critical infrastructure to stay ahead of evolving cybersecurity threats to maintain societal and economic security.
Quantinuum delivers the highest quality quantum randomness, enabling our customers to confront the most advanced cybersecurity challenges present today.
The most common question in the public discourse around quantum computers has been, “When will they be useful?” We have an answer.
Very recently in Nature we announced a successful demonstration of a quantum computer generating certifiable randomness, a critical underpinning of our modern digital infrastructure. We explained how we will be taking a product to market this year, based on that advance – one that could only be achieved because we have the world’s most powerful quantum computer.
Today, we have made another huge leap in a different domain, providing fresh evidence that our quantum computers are the best in the world. In this case, we have shown that our quantum computers can be a useful tool for advancing scientific discovery.
Understanding magnetism
Our latest paper shows how our quantum computer rivals the best classical approaches in expanding our understanding of magnetism. This provides an entry point that could lead directly to innovations in fields from biochemistry, to defense, to new materials. These are tangible and meaningful advances that will deliver real world impact.
To achieve this, we partnered with researchers from Caltech, Fermioniq, EPFL, and the Technical University of Munich. The team used Quantinuum’s System Model H2 to simulate quantum magnetism at a scale and level of accuracy that pushes the boundaries of what we know to be possible.
As the authors of the paper state:
“We believe the quantum data provided by System Model H2 should be regarded as complementary to classical numerical methods, and is arguably the most convincing standard to which they should be compared.”
Our computer simulated the quantum Ising model, a model for quantum magnetism that describes a set of magnets (physicists call them ‘spins’) on a lattice that can point up or down, and prefer to point the same way as their neighbors. The model is inherently “quantum” because the spins can move between up and down configurations by a process known as “quantum tunneling”.
Gaining material insights
Researchers have struggled to simulate the dynamics of the Ising model at larger scales due to the enormous computational cost of doing so. Nobel laureate physicist Richard Feynman, who is widely considered to be the progenitor of quantum computing, once said, “it is impossible to represent the results of quantum mechanics with a classical universal device.” When attempting to simulate quantum systems at comparable scales on classical computers, the computational demands can quickly become overwhelming. It is the inherent ‘quantumness’ of these problems that makes them so hard classically, and conversely, so well-suited for quantum computing.
These inherently quantum problems also lie at the heart of many complex and useful material properties. The quantum Ising model is an entry point to confront some of the deepest mysteries in the study of interacting quantum magnets. While rooted in fundamental physics, its relevance extends to wide-ranging commercial and defense applications, including medical test equipment, quantum sensors, and the study of exotic states of matter like superconductivity.
Instead of tailored demonstrations that claim ‘quantum advantage’ in contrived scenarios, our breakthroughs announced this week prove that we can tackle complex, meaningful scientific questions difficult for classical methods to address. In the work described in this paper, we have proved that quantum computing could be the gold standard for materials simulations. These developments are critical steps toward realizing the potential of quantum computers.
With only 56 qubits in our commercially available System Model H2, the most powerful quantum system in the world today, we are already testing the limits of classical methods, and in some cases, exceeding them. Later this year, we will introduce our massively more powerful 96-qubit Helios system - breaching the boundaries of what until recently was deemed possible.