

Quantum Computers Will Make AI Better
Quantum computers will drive AI to new heights, enabling better accuracy and therefore better performance, and scalable sustainable growth.
Today’s LLMs are often impressive by past standards – but they are far from perfect
Quietly, and determinedly since 2019, we’ve been working on Generative Quantum AI. Our early focus on building natively quantum systems for machine learning has benefitted from and been accelerated by access to the world’s most powerful quantum computers, and quantum computers that cannot be classically simulated.
Our work additionally benefits from being very close to our Helios generation quantum computer, built in Colorado, USA. Helios is 1 trillion times more powerful than our H2 System, which is already significantly more advanced than all other quantum computers available.
While tools like ChatGPT have already made a profound impact on society, a critical limitation to their broader industrial and enterprise use has become clear. Classical large language models (LLMs) are computational behemoths, prohibitively huge and expensive to train, and prone to errors that damage their credibility.
Training models like ChatGPT requires processing vast datasets with billions, even trillions, of parameters. This demands immense computational power, often spread across thousands of GPUs or specialized hardware accelerators. The environmental cost is staggering—simply training GPT-3, for instance, consumed nearly 1,300 megawatt-hours of electricity, equivalent to the annual energy use of 130 average U.S. homes.
This doesn’t account for the ongoing operational costs of running these models, which remain high with every query.
Despite these challenges, the push to develop ever-larger models shows no signs of slowing down.
Enter quantum computing. Quantum technology offers a more sustainable, efficient, and high-performance solution—one that will fundamentally reshape AI, dramatically lowering costs and increasing scalability, while overcoming the limitations of today's classical systems.
Quantum Natural Language Processing: A New Frontier
At Quantinuum we have been maniacally focused on “rebuilding” machine learning (ML) techniques for Natural Language Processing (NLP) using quantum computers.
Our research team has worked on translating key innovations in natural language processing — such as word embeddings, recurrent neural networks, and transformers — into the quantum realm. The ultimate goal is not merely to port existing classical techniques onto quantum computers but to reimagine these methods in ways that take full advantage of the unique features of quantum computers.
We have a deep bench working on this. Our Head of AI, Dr. Steve Clark, previously spent 14 years as a faculty member at Oxford and Cambridge, and over 4 years as a Senior Staff Research Scientist at DeepMind in London. He works closely with Dr. Konstantinos Meichanetzidis, who is our Head of Scientific Product Development and who has been working for years at the intersection of quantum many-body physics, quantum computing, theoretical computer science, and artificial intelligence.
A critical element of the team’s approach to this project is avoiding the temptation to simply “copy-paste”, i.e. taking the math from a classical version and directly implementing that on a quantum computer.
This is motivated by the fact that quantum systems are fundamentally different from classical systems: their ability to leverage quantum phenomena like entanglement and interference ultimately changes the rules of computation. By ensuring these new models are properly mapped onto the quantum architecture, we are best poised to benefit from quantum computing’s unique advantages.
These advantages are not so far in the future as we once imagined – partially driven by our accelerating pace of development in hardware and quantum error correction.
Making computers “talk”- a short history
The ultimate problem of making a computer understand a human language isn’t unlike trying to learn a new language yourself – you must hear/read/speak lots of examples, memorize lots of rules and their exceptions, memorize words and their meanings, and so on. However, it’s more complicated than that when the “brain” is a computer. Computers naturally speak their native languages very well, where everything from machine code to Python has a meaningful structure and set of rules.
In contrast, “natural” (human) language is very different from the strict compliance of computer languages: things like idioms confound any sense of structure, humor and poetry play with semantics in creative ways, and the language itself is always evolving. Still, people have been considering this problem since the 1950’s (Turing’s original “test” of intelligence involves the automated interpretation and generation of natural language).
Up until the 1980s, most natural language processing systems were based on complex sets of hand-written rules. Starting in the late 1980s, however, there was a revolution in natural language processing with the introduction of machine learning algorithms for language processing.
Initial ML approaches were largely “statistical”: by analyzing large amounts of text data, one can identify patterns and probabilities. There were notable successes in translation (like translating French into English), and the birth of the web led to more innovations in learning from and handling big data.
What many consider “modern” NLP was born in the late 2000’s, when expanded compute power and larger datasets enabled practical use of neural networks. Being mathematical models, neural networks are “built” out of the tools of mathematics; specifically linear algebra and calculus.
Building a neural network, then, means finding ways to manipulate language using the tools of linear algebra and calculus. This means representing words and sentences as vectors and matrices, developing tools to manipulate them, and so on. This is precisely the path that researchers in classical NLP have been following for the past 15 years, and the path that our team is now speedrunning in the quantum case.
Quantum Word Embeddings: A Complex Twist
The first major breakthrough in neural NLP came roughly a decade ago, when vector representations of words were developed, using the frameworks known as Word2Vec and GloVe (Global Vectors for Word Representation). In a recent paper, our team, including Carys Harvey and Douglas Brown, demonstrated how to do this in quantum NLP models – with a crucial twist. Instead of embedding words as real-valued vectors (as in the classical case), the team built it to work with complex-valued vectors.
In quantum mechanics, the state of a physical system is represented by a vector residing in a complex vector space, called a Hilbert space. By embedding words as complex vectors, we are able to map language into parameterized quantum circuits, and ultimately the qubits in our processor. This is a major advance that was largely under appreciated by the AI community but which is now rapidly gaining interest.
Using complex-valued word embeddings for QNLP means that from the bottom-up we are working with something fundamentally different. This different “geometry” may provide advantage in any number of areas: natural language has a rich probabilistic and hierarchical structure that may very well benefit from the richer representation of complex numbers.
The Quantum Recurrent Neural Network (RNN)
Another breakthrough comes from the development of quantum recurrent neural networks (RNNs). RNNs are commonly used in classical NLP to handle tasks such as text classification and language modeling.
Our team, including Dr. Wenduan Xu, Douglas Brown, and Dr. Gabriel Matos, implemented a quantum version of the RNN using parameterized quantum circuits (PQCs). PQCs allow for hybrid quantum-classical computation, where quantum circuits process information and classical computers optimize the parameters controlling the quantum system.
In a recent experiment, the team used their quantum RNN to perform a standard NLP task: classifying movie reviews from Rotten Tomatoes as positive or negative. Remarkably, the quantum RNN performed as well as classical RNNs, GRUs, and LSTMs, using only four qubits. This result is notable for two reasons: it shows that quantum models can achieve competitive performance using a much smaller vector space, and it demonstrates the potential for significant energy savings in the future of AI.
In a similar experiment, our team partnered with Amgen to use PQCs for peptide classification, which is a standard task in computational biology. Working on the Quantinuum System Model H1, the joint team performed sequence classification (used in the design of therapeutic proteins), and they found competitive performance with classical baselines of a similar scale. This work was our first proof-of-concept application of near-term quantum computing to a task critical to the design of therapeutic proteins, and helped us to elucidate the route toward larger-scale applications in this and related fields, in line with our hardware development roadmap.
Quantum Transformers - The Next Big Leap
Transformers, the architecture behind models like GPT-3, have revolutionized NLP by enabling massive parallelism and state-of-the-art performance in tasks such as language modeling and translation. However, transformers are designed to take advantage of the parallelism provided by GPUs, something quantum computers do not yet do in the same way.
In response, our team, including Nikhil Khatri and Dr. Gabriel Matos, introduced “Quixer”, a quantum transformer model tailored specifically for quantum architectures.
By using quantum algorithmic primitives, Quixer is optimized for quantum hardware, making it highly qubit efficient. In a recent study, the team applied Quixer to a realistic language modeling task and achieved results competitive with classical transformer models trained on the same data.
This is an incredible milestone achievement in and of itself.
This paper also marks the first quantum machine learning model applied to language on a realistic rather than toy dataset.
This is a truly exciting advance for anyone interested in the union of quantum computing and artificial intelligence, and is in danger of being lost in the increased ‘noise’ from the quantum computing sector where organizations who are trying to raise capital will try to highlight somewhat trivial advances that are often duplicative.
Quantum Tensor Networks. A Scalable Approach
Carys Harvey and Richie Yeung from Quantinuum in the UK worked with a broader team that explored the use of quantum tensor networks for NLP. Tensor networks are mathematical structures that efficiently represent high-dimensional data, and they have found applications in everything from quantum physics to image recognition. In the context of NLP, tensor networks can be used to perform tasks like sequence classification, where the goal is to classify sequences of words or symbols based on their meaning.
The team performed experiments on our System Model H1, finding comparable performance to classical baselines. This marked the first time a scalable NLP model was run on quantum hardware – a remarkable advance.
The tree-like structure of quantum tensor models lends itself incredibly well to specific features inherent to our architecture such as mid-circuit measurement and qubit re-use, allowing us to squeeze big problems onto few qubits.
Since quantum theory is inherently described by tensor networks, this is another example of how fundamentally different quantum machine learning approaches can look – again, there is a sort of “intuitive” mapping of the tensor networks used to describe the NLP problem onto the tensor networks used to describe the operation of our quantum processors.
What we’ve learned so far
While it is still very early days, we have good indications that running AI on quantum hardware will be more energy efficient.
We recently published a result in “random circuit sampling”, a task used to compare quantum to classical computers. We beat the classical supercomputer in time to solution as well as energy use – our quantum computer cost 30,000x less energy to complete the task than Frontier, the classical supercomputer we compared against.
We may see, as our quantum AI models grow in power and size, that there is a similar scaling in energy use: it’s generally more efficient to use ~100 qubits than it is to use ~10^18 classical bits.
Another major insight so far is that quantum models tend to require significantly fewer parameters to train than their classical counterparts. In classical machine learning, particularly in large neural networks, the number of parameters can grow into the billions, leading to massive computational demands.
Quantum models, by contrast, leverage the unique properties of quantum mechanics to achieve comparable performance with a much smaller number of parameters. This could drastically reduce the energy and computational resources required to run these models.
The Path Ahead
As quantum computing hardware continues to improve, quantum AI models may increasingly complement or even replace classical systems. By leveraging quantum superposition, entanglement, and interference, these models offer the potential for significant reductions in both computational cost and energy consumption. With fewer parameters required, quantum models could make AI more sustainable, tackling one of the biggest challenges facing the industry today.
The work being done by Quantinuum reflects the start of the next chapter in AI, and one that is transformative. As quantum computing matures, its integration with AI has the potential to unlock entirely new approaches that are not only more efficient and performant but can also handle the full complexities of natural language. The fact that Quantinuum’s quantum computers are the most advanced in the world, and cannot be simulated classically, gives us a unique glimpse into a future.
The future of AI now looks very much to be quantum and Quantinuum’s Gen QAI system will usher in the era in which our work will have meaningful societal impact.
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
- Quantinuum continues its progress toward fault-tolerant quantum computing, with a series of peer-reviewed breakthroughs in fault-tolerant operations.
- Our progress is not only scientific; it is commercial. By improving logical-qubit reliability and encoding efficiency, Quantinuum is reducing the resource overhead required to scale its quantum computers toward commercially useful workloads.
- These results were achieved on commercial Quantinuum hardware, reinforcing that our architecture is not just setting new standards, but building a practical foundation for customers, partners, and researchers preparing for the fault-tolerant era.
Fault-tolerant quantum computing is the threshold the industry must cross before quantum computers can solve the hardest, highest-value problems with confidence. To be commercially useful at scale, the question is not simply who can build more qubits. It is who can build reliable, efficient, scalable systems that reduce technical risk and accelerate the path to commercial usefulness.
Quantinuum is progressing on that path.
Last year, in partnership with Microsoft, we published a breakthrough in logical computing, demonstrating logical qubits that outperformed their physical counterparts by a factor of 800. We are proud to announce that this work is now being published in Nature, one of the most highly regarded scientific journals in the world.
This work highlights our leading fidelities, as shown in Table 1:
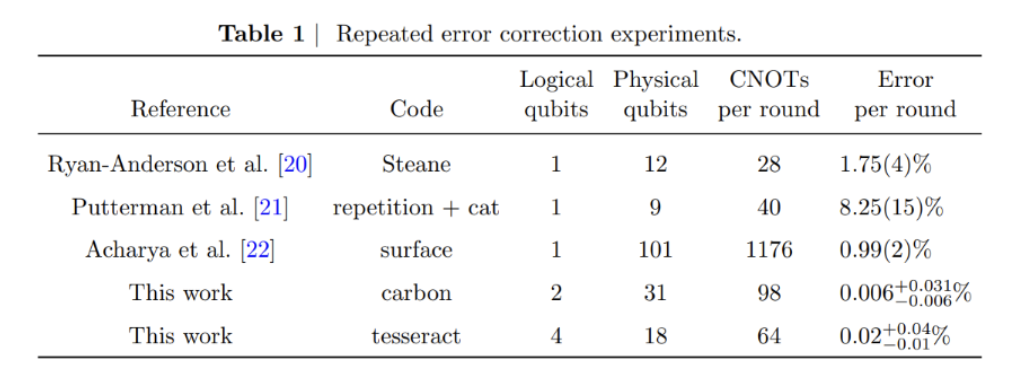
Since then, we’ve accelerated our efforts to reach large-scale fault tolerance and advanced what we believe to be the core building blocks of fault-tolerant quantum computing, from logical-qubit teleportation and multiple error-correction breakthroughs to one of the first meaningful computations using logical qubits. Importantly, these results were achieved on commercial Quantinuum hardware, demonstrating not just scientific progress, but a practical and efficient path toward scalable, customer-ready fault tolerance.
A Recap of Our Recent Technical Progress
Since the work with Microsoft, we achieved a milestone years ahead of schedule, demonstrating high-fidelity teleportation of a logical qubit, which was published in Science, one of the world’s most prestigious journals. Later, we beat our own record in this crucial fault tolerance milestone, thanks to continued improvements to our System Model H2’s fidelity.
Then, a series of results demonstrating more error-correcting milestones (and codes):
- Better than physical results in a high-rate non-local code,
- First-ever demonstration of a single-shot error correcting code (which significantly reduces resource requirements) in 4 dimensions
- Extending qubit lifetimes by 10x with a concatenated code
- Observed fault-tolerance thresholds with concatenated codes
- High fidelity magic states and a fully fault tolerant universal gate set in two different papers
Recently, we topped ourselves yet again by performing one of the first meaningful computations with logical qubits – exploring key questions in materials and magnetism, using logical qubits with better error rates than their physical counterparts. This result also includes a leading “encoding rate” squeezing 48 logical qubits out of just 98 physical qubits, emphasizing how our architecture helps to support large scale fault tolerance without enormous resource costs.
It is worth noting that all these results were achieved on our commercial hardware, not on one-off laboratory test-stands – reflecting the performance that we are able to deliver to our customers.
We also did crucial theoretical work, exploring new options for error correction that can reduce resource requirements, time to solution, and shorten the timeline to large scale fault tolerance.
Commercial Implications and the Road Ahead
We believe the commercial implication is clear: Quantinuum is reducing the uncertainty around the path to fault-tolerant quantum computing. Our architecture, hardware fidelity, full-stack control, and error-correction progress are converging into a practical roadmap for systems that can support valuable scientific and commercial workloads.
For those evaluating when quantum computing will become strategically relevant, we believe the signal is also increasingly clear: the fault-tolerant era is no longer a distant concept. It is becoming an engineering reality, and Quantinuum is leading the way.
- University of Southern Denmark (SDU) to use Quantinuum Helios, supported by the Danish e-Infrastructure Consortium (DeiC)
- Access to Helios enables SDU to test and refine fault-tolerant algorithms and error-correction codes under realistic hardware conditions
- The collaboration supports at a scale of 48 logical qubits, positioning Denmark at the forefront of scalable, practical quantum computing
- Researchers exploring the scientific foundations for future development of applications in fields including pharmaceuticals, finance, and defense
Progress in quantum computing is measured by hardware advances plus the algorithms and quantum error-correction codes that turn quantum systems into useful computational tools.
Thanks to recent hardware advances, researchers are increasingly sharpening their tools to probe the performance of quantum algorithms and understand how they behave in realistic conditions – where stability, system architecture and algorithm design all shape performance.
A new Denmark-based collaboration between the University of Southern Denmark (SDU), Quantinuum, and the Danish e-Infrastructure Consortium (DeiC) will utilize Quantinuum Helios. Researchers at the SDU’s Centre for Quantum Mathematics, led by Jørgen Ellegaard Andersen, will use Helios to pursue research into topological quantum computing.
Their work could help explain how and why successful quantum algorithms perform as they do, informing the development of high-performance algorithms suited to emerging quantum systems. They’re exploring the scientific foundations that support future quantum applications across areas including pharmaceuticals, finance, and defense.
“We are thrilled to gain access to Quantinuum’s high-fidelity Helios system. This collaboration gives us a unique opportunity to test the limits of our algorithms and evaluate system performance, while advancing fundamental research and laying the foundation for future applications.”
— Professor Jørgen Ellegaard Andersen, Director of the Centre for Quantum Mathematics at University of Southern Denmark
Why topological methods matter
Topological quantum computing is an area of research that connects quantum computation with deep mathematical structures. It includes the study of error correcting codes known as surface codes that encode quantum information in the global properties of systems of logical qubits.
The research team will explore how these codes behave, and how they may support the development of fault-tolerant quantum algorithms in practical implementations under realistic conditions.
This distinction between theory and practical implementation matters. In theory, topological approaches offer a rich framework for designing algorithms and error-correcting codes. In practice, researchers need to understand how those ideas perform when implemented on real systems, where questions of noise, stability, overhead, and scaling become central. The collaboration will allow the SDU team to investigate these questions directly.
New ways to benchmark quantum processors
Beyond individual algorithms and codes, the research will also develop tools for benchmarking quantum processors. The goal is to develop new ways to characterize fidelity and stability in regimes that can be difficult to access.
The team will also explore hybrid quantum–classical approaches, including machine-learning techniques assisted by quantum hardware, to study the mathematical structures at the heart of topological quantum computing. This work reflects a broader field of research in which quantum and classical methods are used together, each contributing to parts of a computational problem.
Strengthening Denmark’s quantum ecosystem
The collaboration reflects the growing role of national quantum infrastructure in supporting research and talent development. Denmark has a long tradition of scientific innovation, and this collaboration is intended to support the country’s continued development in quantum technology.
The initiative is supported by DeiC, which played a central role in securing funding and enabling access to Quantinuum’s systems. DeiC has been assigned a particular role in developing and coordinating quantum infrastructure initiatives for the benefit of universities and industry, operating without its own commercial, sectoral, or geographical interests. This includes securing dedicated access to quantum computers, producing advisory services and supporting the development of new talent in the Danish quantum sector.
“DeiC’s special effort to secure funding and access for this research initiative is rooted in our organization’s role in relation to the Danish Government’s strategy for quantum technology.”
— Henrik Navntoft Sønderskov, Head of Quantum at Danish e-Infrastructure Consortium
This collaboration promises to accelerate the development of practical algorithms. It is grounded in fundamental science – but its focus is practical: discovering and testing mathematical approaches to topological quantum computing that can be implemented, evaluated, and improved on real quantum hardware.
That work requires both theoretical insight and access to a system such as Helios capable of supporting meaningful scientific work.

This month, Quantinuum welcomed its global user community to the first-ever Q-Net Connect, an annual forum designed to spark collaboration, share insights, and accelerate innovation across our full-stack quantum computing platforms. Over two days, users came together not only to learn from one another, but to build the relationships and momentum that we believe will help define the next chapter of quantum computing.
Q-Net Connect 2026 drew over 170 attendees from around the world to Denver, Colorado, including representatives from commercial enterprises and startups, academia and research institutions, and the public sector and non-profits - all users of Quantinuum systems.
The program was packed with inspiring keynotes, technical tracks, and customer presentations. Attendees heard from leaders at Quantinuum, as well as our partners at NVIDIA, JPMorganChase and BlueQubit; professors from the University of New Mexico, the University of Nottingham and Harvard University; national labs, including NIST, Oak Ridge National Laboratory, Sandia National Laboratories and Los Alamos National Laboratory; and other distinguished guests from across the global quantum ecosystem.
Congratulations to Q-Net Connect 2026 Award Recipients!
The mission of the Quantinuum Q-Net user community is to create a space for shared learning, collaboration and connection for those who adopt Quantinuum’s hardware, software and middleware platform. At this year’s Q-Net Connect, we awarded four organizations who made notable efforts to champion this effort.
- JPMorganChase received the ‘Guppy Adopter Award’ for their exemplary adoption of our quantum programming language, Guppy, in their research workflows.
- Phasecraft, a UK and US-based quantum algorithms startup, received the ‘Rising Star’ award for demonstrating exceptional early impact and advancing science using Quantinuum hardware, which they published in a December 2025 paper.
- Qedma, a quantum software startup, received the ‘Startup Partner Engagement’ award for their sustained engagement with Quantinuum platforms dating back to our first commercially deployed quantum computer, H1.
- Anna Dalmasso from the University of Nottingham received our ‘New Student Award’ for her impressive debut project on Quantinuum hardware and for delivering outstanding results as a new Q-Net student user.
Congratulations, again, and thank you to everyone who contributed to the success of the first Q-Net Connect!
Become a Q-Net Member
Q-Net offers year‑round support through user access, developer tools, documentation, trainings, webinars, and events. Members enjoy many exclusive benefits, including being the first to hear about exclusive content, publications and promotional offers.
By joining the community, you will be invited to exclusive gatherings to hear about the latest breakthroughs and connect with industry experts driving quantum innovation. Members also get access to Q‑Net Connect recordings and stay connected for future community updates.